
XenServer has supported passthrough for PCI devices since XenServer 6.0 and this has been the defacto method for providing a GPU to a guest. With the advent of NVIDIA's vGPU-capable GRID K1/K2 cards it will now be possible to carve up a GPU into smaller pieces yielding a more scalable solution to boosting graphics performance within virtual machines.
NVIDIA currently offer two cards, the K1 and the K2. The K1 has four GPUs and the K2, two GK107 GPUs. Each of these will be exposed through Xapi so a host with a single K1 card will have access to four independent PGPUs.
Each of the GPUs can then be subdivided into vGPUs. For each type of PGPU, there are a few options of vGPU type which consume different amounts of the PGPU. The K1 and K2 cards can cuurently be configured in the following ways:
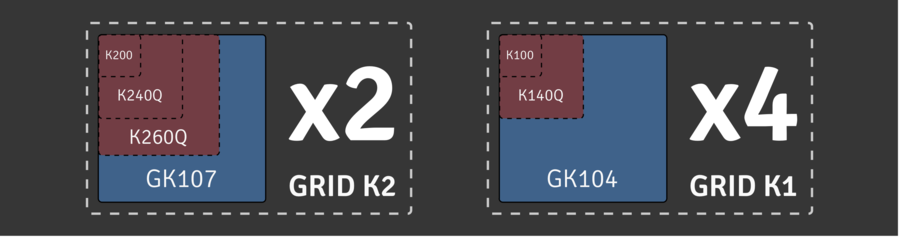
Note, this diagram is not to scale, the PGPU resource required by each vGPU type is as follows:
| vGPU type | PGPU kind | vGPUs / PGPU |
|---|---|---|
| k100 | GK104 | 8 |
| k140Q | GK104 | 4 |
| k200 | GK107 | 8 |
| k240Q | GK107 | 4 |
| k260Q | GK107 | 2 |
Currently each physical GPU (PGPU) only supports homogeneous vGPU configurations but different configurations are supported on different PGPUs across a single K1/K2 card. This means that, for example, a host with a K1 card can run 64 VMs with k100 vGPUs (8 per PGPU).
A new display type has been added to the device model:
@@ -4519,6 +4522,7 @@ static const QEMUOption qemu_options[] =
/* Xen tree options: */
{ "std-vga", 0, QEMU_OPTION_std_vga },
+ { "vgpu", 0, QEMU_OPTION_vgpu },
{ "videoram", HAS_ARG, QEMU_OPTION_videoram },
{ "d", HAS_ARG, QEMU_OPTION_domid }, /* deprecated; for xend compatibility */
{ "domid", HAS_ARG, QEMU_OPTION_domid },
With this in place, qemu can now be started using a new option that will
enable it to communicate with a new display emulator, vgpu to expose the
graphics device to the guest. The vgpu binary is responsible for handling the
VGX-capable GPU and, once it has been successfully passed through, the in-guest
drivers can be installed in the same way as when it detects new hardware.
The diagram below shows the relevant parts of the architecture for this project.
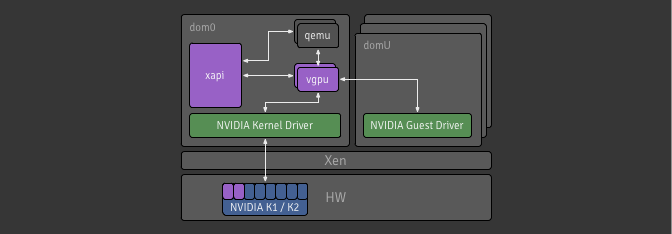
A lot of work has gone into the toolstack to handle the creation and management
of VMs with vGPUs. We revised our data model, introducing a semantic link
between VGPU and PGPU objects to help with utilisation tracking; we
maintained the GPU_group concept as a pool-wide abstraction of PGPUs
available for VMs; and we added VGPU_types which are configurations for
VGPU objects.
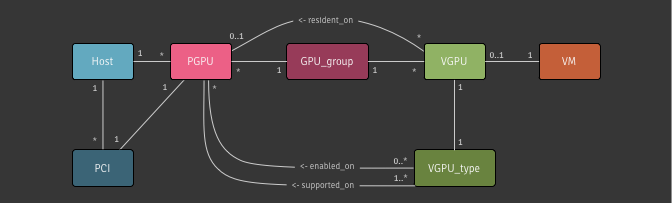
Aside: The VGPU type in Xapi's data model predates this feature and was synonymous with GPU-passthrough. A VGPU is simply a display device assigned to a VM which may be a vGPU (this feature) or a whole GPU (a VGPU of type passthrough).
VGPU_types can be enabled/disabled on a per-PGPU basis allowing for
reservation of particular PGPUs for certain workloads. VGPUs are allocated on
PGPUs within their GPU group in either a depth-first or breadth-first
manner, which is configurable on a per-group basis.
To create a VGPU of a given type you can use vgpu-create:
$ xe vgpu-create vm-uuid=... gpu-group-uuid=... vgpu-type-uuid=...
To see a list of VGPU types available for use on your XenServer, run the
following command. Note: these will only be populated if you have installed the
relevant NVIDIA RPMs and if there is hardware installed on that host supported
each type. Using params=all will display more information such as the maximum
number of heads supported by that VGPU type and which PGPUs have this type
enabled and supported.
$ xe vgpu-type-list [params=all]
To access the new and relevant parameters on a PGPU (i.e.
supported_VGPU_types, enabled_VGPU_types, resident_VGPUs) you can use
pgpu-param-get with param-name=supported-vgpu-types
param-name=enabled-vgpu-types and param-name=resident-vgpus respectively.
Or, alternatively, you can use the following command to list all the parameters
for the PGPU. You can get the types supported or enabled for a given PGPU:
$ xe pgpu-list uuid=... params=all
vgpu process is started, if
necessary, before Qemu.