
LVHD is a block-based storage system built on top of Xapi and LVM. LVHD disks are represented as LVM LVs with vhd-format data inside. When a disk is snapshotted, the LVM LV is "deflated" to the minimum-possible size, just big enough to store the current vhd data. All other disks are stored "inflated" i.e. consuming the maximum amount of storage space. This proposal describes how we could add dynamic thin-provisioning to LVHD such that
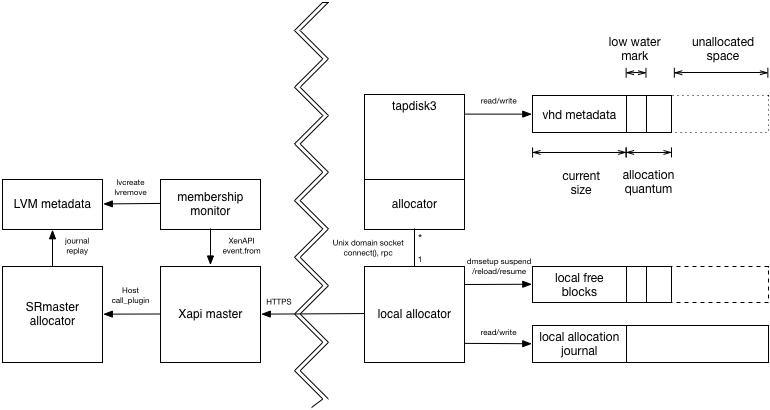
All VM disk writes are channeled through tapdisk3 which keeps
track of how much space remains reserved in the LVM LV. When the
free space drops below a "low-water mark" (configurable via a host
config file), tapdisk3 opens a connection to a "local allocator"
process and requests more space asynchronously. If tapdisk3
notices the free space approach zero then it should start to slow
I/O in order to provide the local allocator more time.
Eventually if tapdisk3 runs
out of space before the local allocator can satisfy the request then
guest I/O will block. Note Windows VMs will start to crash if guest
I/O blocks for more than 70s.
Every host has a "local allocator" daemon which manages a host-wide
pool of blocks (represented by an LVM LV) and provides them to tapdisk3
on demand. When it receives a request, the local allocator decides
which blocks to provide from its local free pool, writes to the journal
and then reloads the device mapper table to extend the LV. The journal
is replayed on the SRmaster when any VDI on the host is deactivated.
The local allocator also has a "low-water mark" (configurable via a host config file) and will request additional blocks from the SRmaster when it is running low.
Consider what will happen if a host fails when HA is disabled:
Therefore we recommend that users enable HA and only disable it for short periods of time. Note that, unlike other thin-provisioning implementations, we will allow HA to be disabled.
When a host calls SMAPI sr_attach, it will attach two host-local
LVs:
host-<uuid>-free: these are free blocks cached on the host.host-<uuid>-journal: this contains a sequence of block allocation
records describing where the free blocks have been allocated.On sr_attach and sr_detach the journal should be replayed
and then emptied. The journal replay code must be run on the SRmaster
since this host is the only one with read/write access to the LVM metadata.
For ease of debugging and troubleshooting, we should create command-line tools to dump and replay the journal.
The local allocator process should export RRD datasources over shared memory named
sr_<SR uuid>_<host uuid>_free: the number of free blocks in
the local cachesr_<SR uuid>_<host uuid>_allocations: a counter of the number
of times the local cache had to be refilled from the SRmasterThe admin should examine the allocations counter in particular as if the rate of allocations is too high it means the local host's allocation quantum should be increased. For a particular workload, the allocation quantum should be increased just enough to prevent any allocations being necessary during the HA timeout period.
tapdisk3 will be modified to
/etc/tapdisk3.conf/etc/tapdisk3.conf/etc/tapdisk3.confThe request has the following format:
| Octet offsets | Name | Description |
|---|---|---|
| 0,1 | tl | Total length (including this field) of message (in network byte order) |
| 2 | type | The value '0' indicating an extend request |
| 3 | nl | The length of the LV name in octets, including NULL terminator |
| 4,...,4+nl-1 | name | The LV name |
| 4+nl-12+nl-1 | vdi_size | The virtual size of the logical VDI (in network byte order) |
| 12+nl-20+nl-1 | lv_size | The current size of the LV (in network byte order) |
| 20+nl-28+nl-1 | cur_size | The current size of the vhd metadata (in network byte order) |
The response is a single byte value "0" which is a signal to re-examime the LV size. The request will block indefinitely until it succeeds. The request will block for a long time if
There is one local allocator process per attached SR. The process will be
spawned by the SM sr_attach call, and sent a shutdown message from
the sr_detach call.
The sr_attach call shall
--listen <path> where <path> is a name for the local Unix domain
socket.When the host allocator process starts up it will read the host local journal and
The sr_detach call shall
The shutdown request has the following format:
| Octet offsets | Name | Description |
|---|---|---|
| 0,1 | tl | Total length (including this field) of message (in network byte order) |
| 2 | type | The value '1' indicating a shutdown request |
There is no response to the shutdown request. The local allocator will terminate as soon as it is able.
When the local allocator receives an extend request it will examine
the device mapper tables of the local free block LV and choose the first
free blocks, up to the "vdi-allocation-quantum" in the /etc/tapdisk-allocator.conf.
The local allocator will append an entry to the host local journal recording
this choice of blocks (always using unambiguous physical block addresses).
Once the journal entry it committed, the host local allocator will reload
the device mapper tables of the tapdisk3 device and then reply to
tapdisk.
TODO: describe the journal format
TODO: describe the journal replay tool here
The SRmaster allocator is a XenAPI host plugin lvhd-allocator.
The local host allocator calls the SRmaster allocator when it is
running low on free blocks on the host. The SRmaster allocator will
perform an LVM resize of the host's local free block LV.
TODO: what should the default resize amount be?
The role of the membership monitor is to
We shall
host-pre-declare-dead script to replay the journalHost.declare_dead to call host-pre-declare-dead before
the VMs are unlockedhost-pre-forget hook type which will be called just before a Host
is forgottenhost-pre-forget script to destroy the host's local LVsRolling upgrade should work in the usual way. As soon as the pool master has been upgraded, hosts will be able to use thin provisioning when new VDIs are attached. A VM suspend/resume/reboot or migrate will be needed to turn on thin provisioning for existing running VMs.
A pool may be safely downgraded to a previous version without thin provisioning provided that storage is unplugged cleanly so that journals are replayed. We should document how the journal replay tool works so people can work around problems for themselves. If journals are not replayed then VM disks will be corrupted.
If HA is enabled:
xhad elects a new master if necessaryxhad tells Xapi which hosts are alive and which have failed.Xapi runs the host-pre-declare-dead scripts for every failed hosthost-pre-declare-dead scripts replay the host local journals and
update the LVM metadata on the SRmasterXapi unlocks the VMs and restarts them on new hosts.If HA is not enabled:
Xapi which hosts have failed with xe host-declare-deadXapi runs the host-pre-declare-dead scripts for every failed hosthost-pre-declare-dead scripts replay the host local journals and
update the LVM metadata on the SRmasterXapi unlocks the VMsDm-thin also uses 2 local LVs: one for the "thin pool" and one for the metadata. After replaying our journal we could potentially delete our host local LVs and switch over to dm-thin.